Projektowanie relacyjnej bazy danych to proces tworzenia struktury, która efektywnie przechowuje i zarządza danymi w sposób zorganizowany. Najprościej mówiąc, to plan budowy bazy danych, który określa, jakie informacje będziemy przechowywać, jak będą one powiązane i jak będziemy je przetwarzać. Poprawna kolejność etapów projektowania jest kluczowa dla sukcesu całego przedsięwzięcia.
Oto prawidłowa kolejność etapów projektowania relacyjnej bazy danych:
- Analiza wymagań: To pierwszy i najważniejszy krok. Rozmawiamy z przyszłymi użytkownikami bazy danych, aby zrozumieć ich potrzeby i wymagania. Określamy, jakie dane będą potrzebne, jak często będą wykorzystywane i jakie operacje będą na nich wykonywane. Przykład: Jeśli projektujemy bazę danych dla sklepu internetowego, musimy wiedzieć, jakie informacje chcemy przechowywać o produktach (nazwa, cena, opis, zdjęcie), o klientach (imię, nazwisko, adres, historia zamówień) i o zamówieniach (data, status, lista produktów).
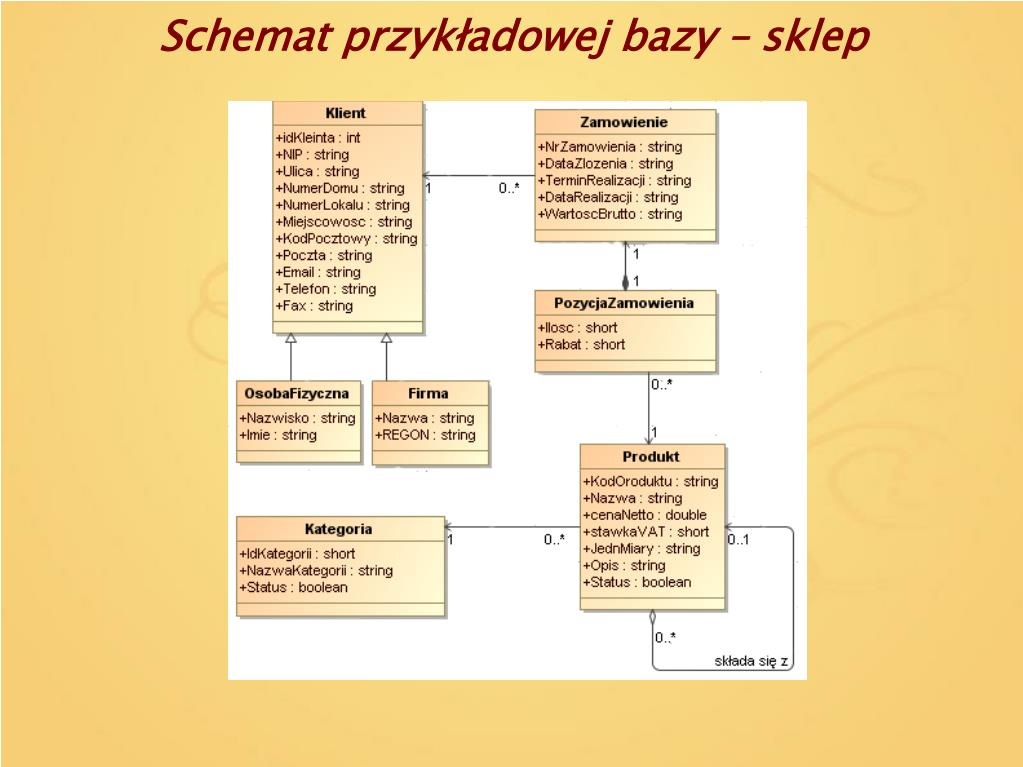
- Projekt koncepcyjny (Modelowanie ERD): Na tym etapie tworzymy graficzny model danych, zwany Diagramem Zależności Encji (ERD - Entity-Relationship Diagram). Model ten przedstawia encje (obiekty, o których przechowujemy informacje – np. Klient, Produkt, Zamówienie), ich atrybuty (cechy encji – np. imię klienta, cena produktu) oraz relacje między encjami (np. Klient składa Zamówienie). Przykład: ERD dla sklepu internetowego pokaże encję "Klient" powiązaną relacją "składa" z encją "Zamówienie".
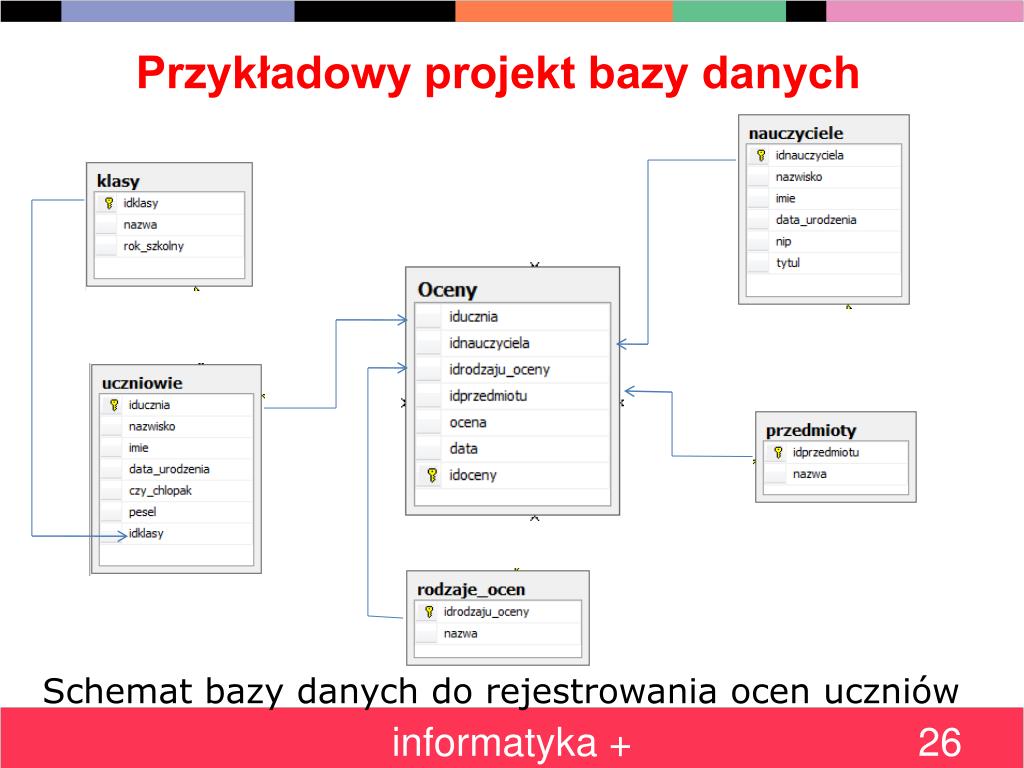
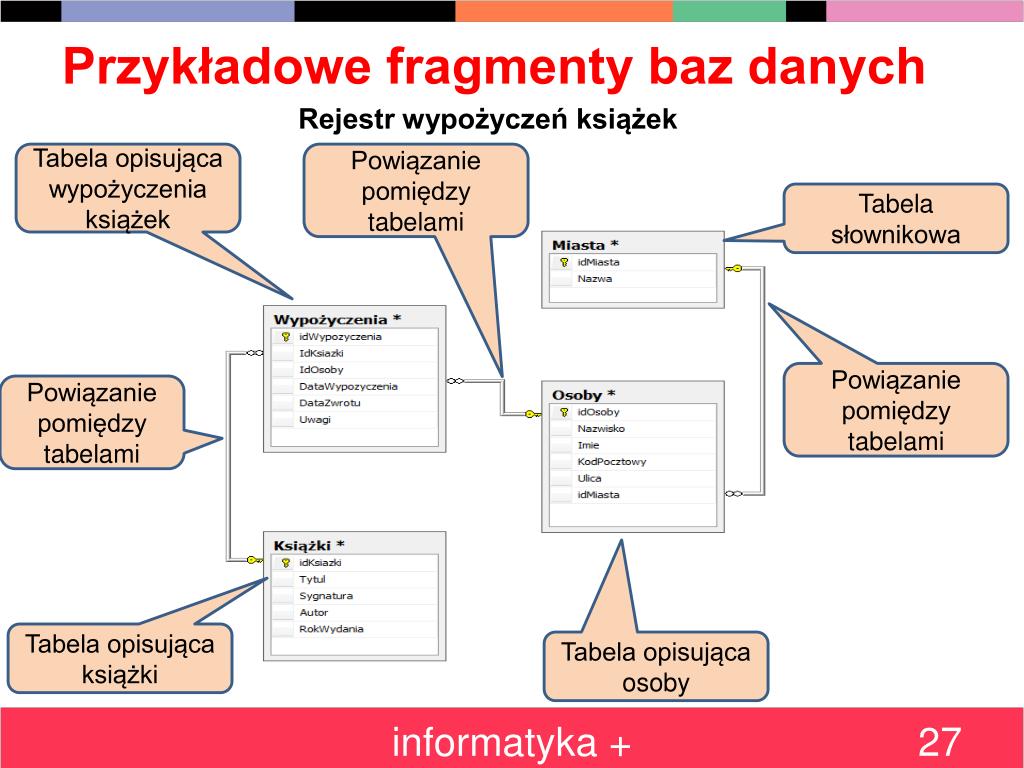
- Projekt logiczny (Normalizacja): Przekształcamy model koncepcyjny w model logiczny, który opisuje strukturę bazy danych w sposób zrozumiały dla systemu zarządzania bazą danych (DBMS). Kluczowym elementem tego etapu jest normalizacja, czyli proces eliminowania redundancji (powtarzających się danych) i zapobiegania anomaliom podczas aktualizacji danych. Normalizacja polega na rozkładaniu tabel na mniejsze, bardziej wyspecjalizowane tabele, połączone relacjami kluczy obcych. Przykład: Zamiast przechowywać adres klienta w tabeli "Zamówienie", tworzymy osobną tabelę "Adresy" i łączymy ją z tabelą "Klienci" i "Zamówienia" za pomocą kluczy obcych.
- Projekt fizyczny: Określamy szczegóły implementacyjne bazy danych, takie jak typy danych dla poszczególnych atrybutów, indeksy, partycje i inne parametry, które wpływają na wydajność bazy danych. Wybieramy również konkretny system zarządzania bazą danych (DBMS), np. MySQL, PostgreSQL, SQL Server. Przykład: Dla atrybutu "cena produktu" wybieramy typ danych DECIMAL, a dla atrybutu "data zamówienia" - typ DATETIME. Tworzymy indeks na kolumnie "nazwa produktu", aby przyspieszyć wyszukiwanie produktów po nazwie.
- Implementacja: Tworzymy tabele w bazie danych, definiujemy relacje między nimi i wprowadzamy początkowe dane.
- Testowanie i Optymalizacja: Testujemy działanie bazy danych, sprawdzamy poprawność danych i wydajność zapytań. W razie potrzeby wprowadzamy poprawki i optymalizujemy strukturę bazy danych.
Zastosowania praktyczne:
Must Read
Znajomość tych etapów jest niezbędna dla każdego, kto zajmuje się tworzeniem aplikacji internetowych, systemów zarządzania treścią (CMS), systemów e-commerce i wielu innych. Nawet jeśli nie jesteś programistą baz danych, zrozumienie podstaw projektowania relacyjnych baz danych pomoże Ci lepiej zrozumieć, jak działają aplikacje, z których korzystasz na co dzień i jak przechowywane są Twoje dane.
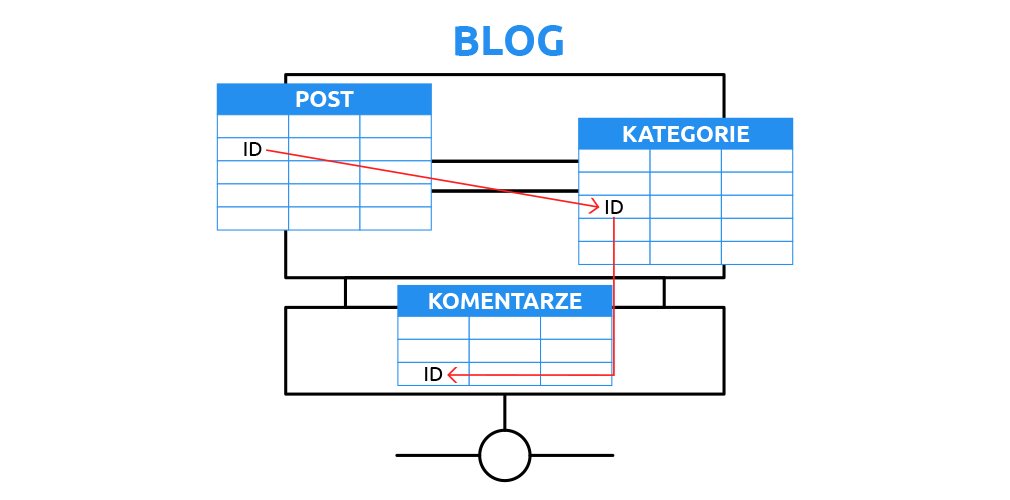
Na przykład, gdy korzystasz z Facebooka, informacje o Twoich znajomych, postach i komentarzach są przechowywane w relacyjnej bazie danych. Prawidłowe zaprojektowanie tej bazy danych jest kluczowe dla sprawnego działania platformy.