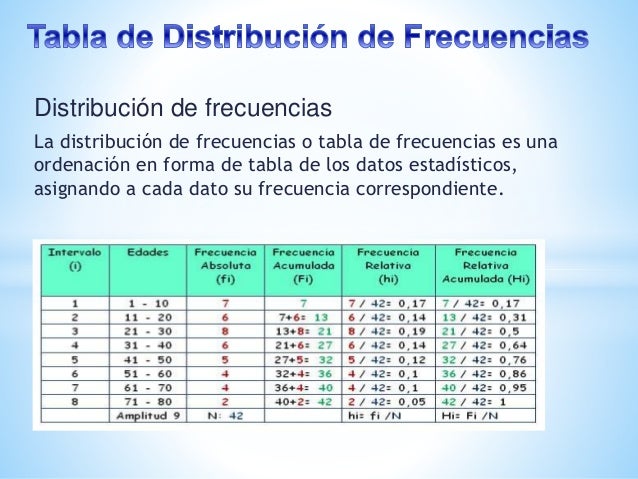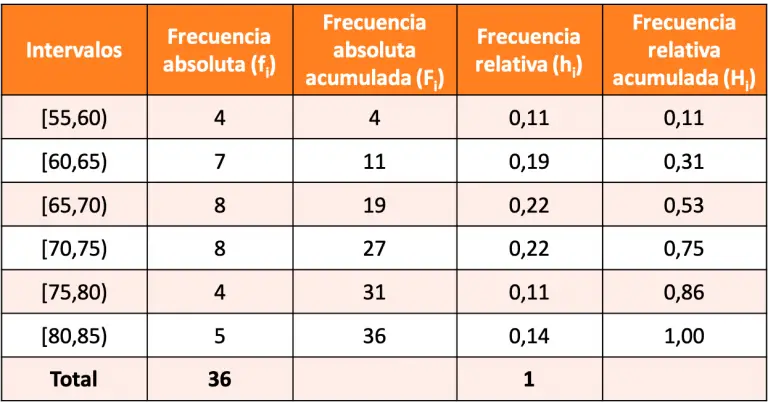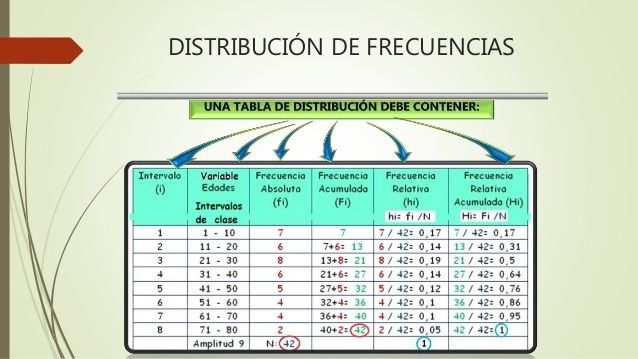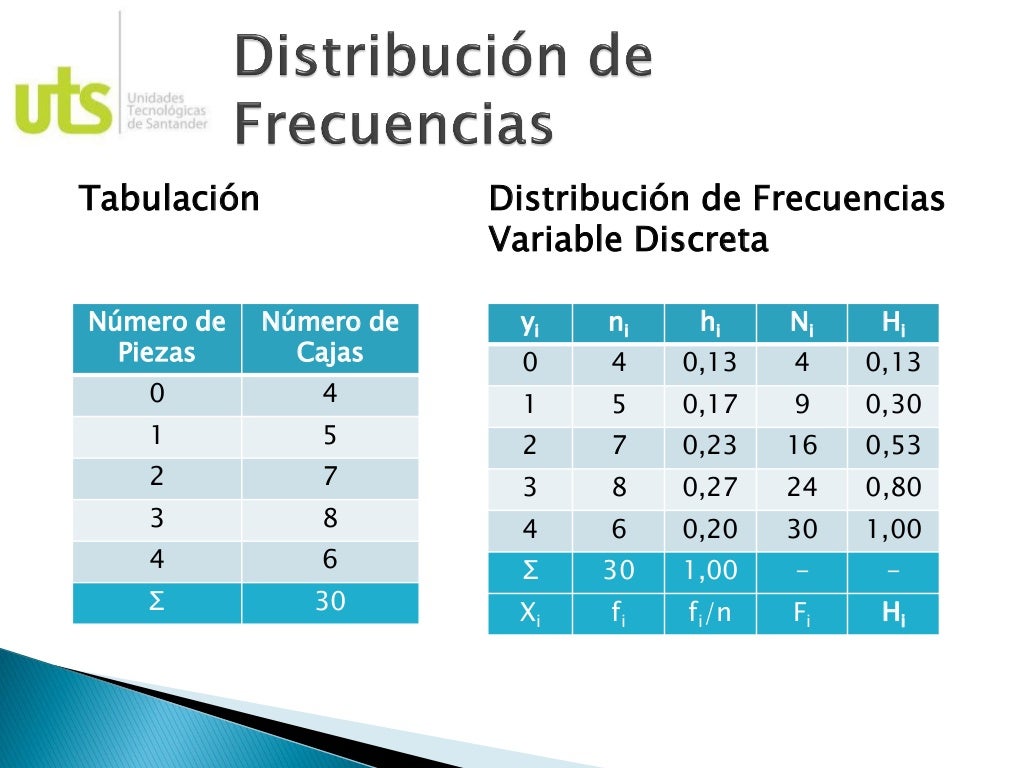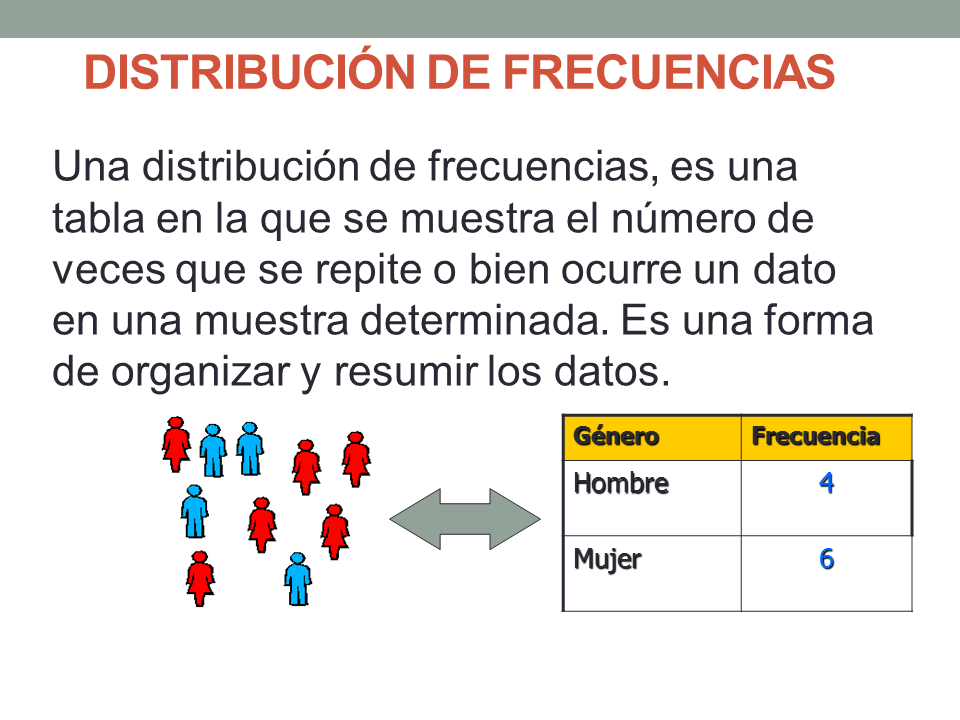
Una distribución de frecuencia es una tabla que organiza datos en categorías o intervalos, mostrando el número de veces (la frecuencia) que cada valor o grupo de valores ocurre en un conjunto de datos. Es una herramienta esencial para resumir y visualizar datos, permitiendo identificar patrones, tendencias y la dispersión de los mismos. Se usa en campos tan diversos como marketing (analizar preferencias del cliente), investigación científica (estudiar resultados experimentales) o control de calidad (monitorear defectos).
¿Cómo se construye? Paso a Paso
Aquí te presentamos una guía rápida para construir una distribución de frecuencia:
- Paso 1: Recopila tus datos. Debes tener un conjunto de datos sin procesar. Por ejemplo, las edades de 20 personas en una fiesta: 22, 25, 28, 30, 22, 24, 26, 28, 32, 23, 27, 29, 31, 23, 25, 27, 29, 33, 24, 26.
- Paso 2: Determina el rango. El rango es la diferencia entre el valor máximo y el mínimo. En nuestro ejemplo, el rango es 33 - 22 = 11.
- Paso 3: Decide el número de clases (intervalos). No existe una regla fija, pero generalmente se recomienda entre 5 y 15 clases. Un número muy pequeño oculta detalles, uno muy grande dificulta la visión general. Para este ejemplo, usemos 5 clases.
- Paso 4: Calcula el ancho de clase. Divide el rango por el número de clases. En nuestro caso, 11 / 5 = 2.2. Redondea a un número conveniente, como 3. Esto significa que cada intervalo abarcará 3 edades.
- Paso 5: Define los límites de las clases. Empieza con el valor mínimo (22) y agrega el ancho de clase para definir cada intervalo:
- Clase 1: 22 - 24
- Clase 2: 25 - 27
- Clase 3: 28 - 30
- Clase 4: 31 - 33
- Clase 5: 34 - 36
- Paso 6: Cuenta las frecuencias. Cuenta cuántos valores de tus datos caen en cada clase. Por ejemplo:
- Clase 1 (22-24): 6
- Clase 2 (25-27): 6
- Clase 3 (28-30): 4
- Clase 4 (31-33): 3
- Clase 5 (34-36): 0
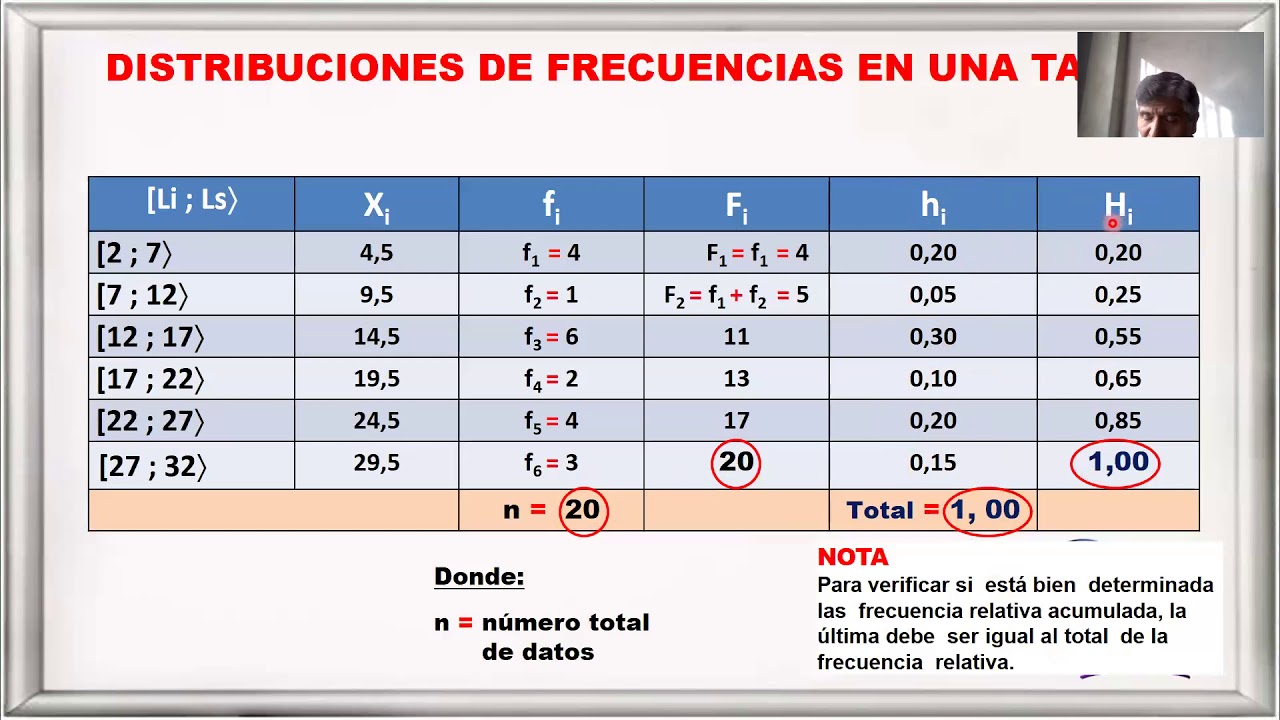
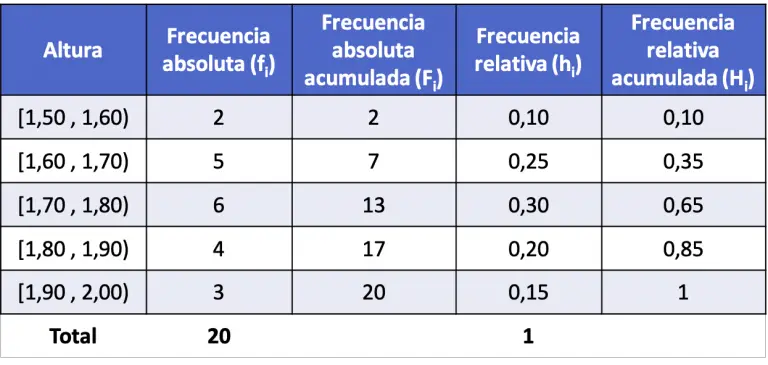
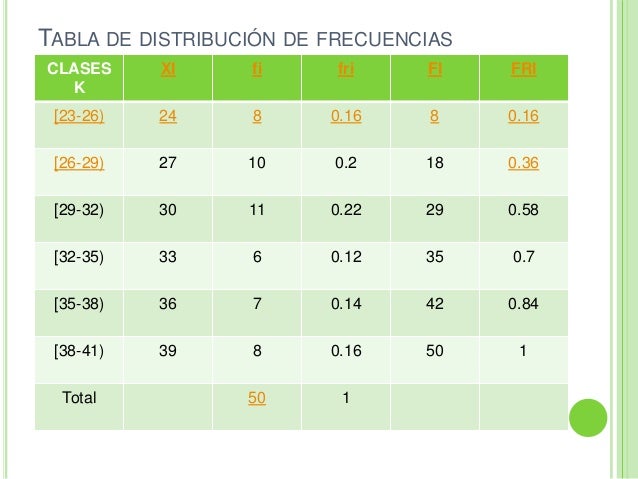
- Paso 7: Construye la tabla de distribución de frecuencia. Organiza las clases y sus frecuencias en una tabla. Puedes añadir columnas para frecuencia relativa (frecuencia de la clase / total de datos) y frecuencia acumulada (suma de las frecuencias hasta esa clase) para un análisis más profundo.
¡Listo! Ahora puedes analizar tu distribución de frecuencia para entender mejor tus datos.