Para abordar la construcción de un Analizador Lexicográfico, Sintáctico y Semántico en Java, primero dividiremos el problema en etapas manejables.
Inicialmente, se necesita un Entendimiento Profundo de la gramática del lenguaje que se va a analizar. Este conocimiento es crucial. Se debe elegir una gramática formal para representar las reglas del lenguaje. ¿Qué gramática se adapta mejor al lenguaje objetivo?
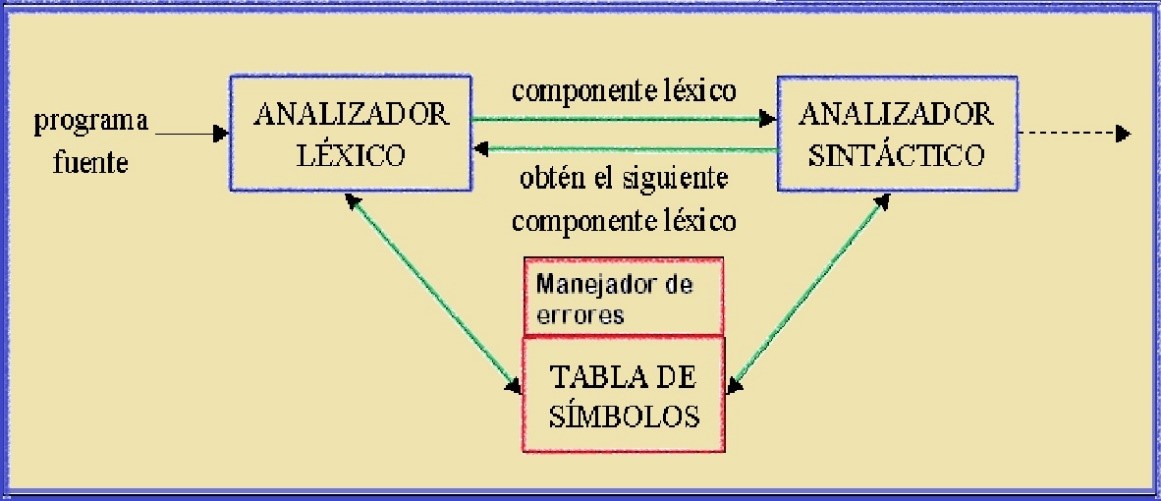
Análisis Lexicográfico
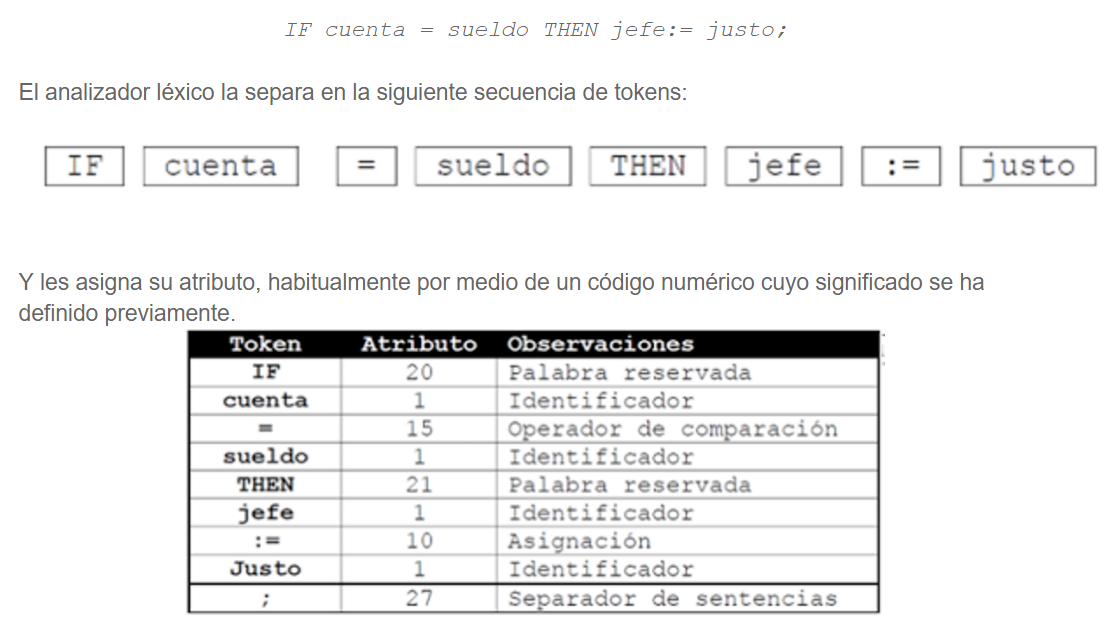
Comencemos con el Análisis Lexicográfico. Aquí, el objetivo es dividir el código fuente en tokens. Un token es una unidad léxica significativa (palabras clave, identificadores, operadores, etc.).
Must Read
Para lograr esto, se puede usar Expresiones Regulares. Estas expresiones definen patrones para cada tipo de token. Se define un patrón para identificar números enteros. Luego, otro para identificar identificadores. ¿Cómo se manejan los comentarios y espacios en blanco?
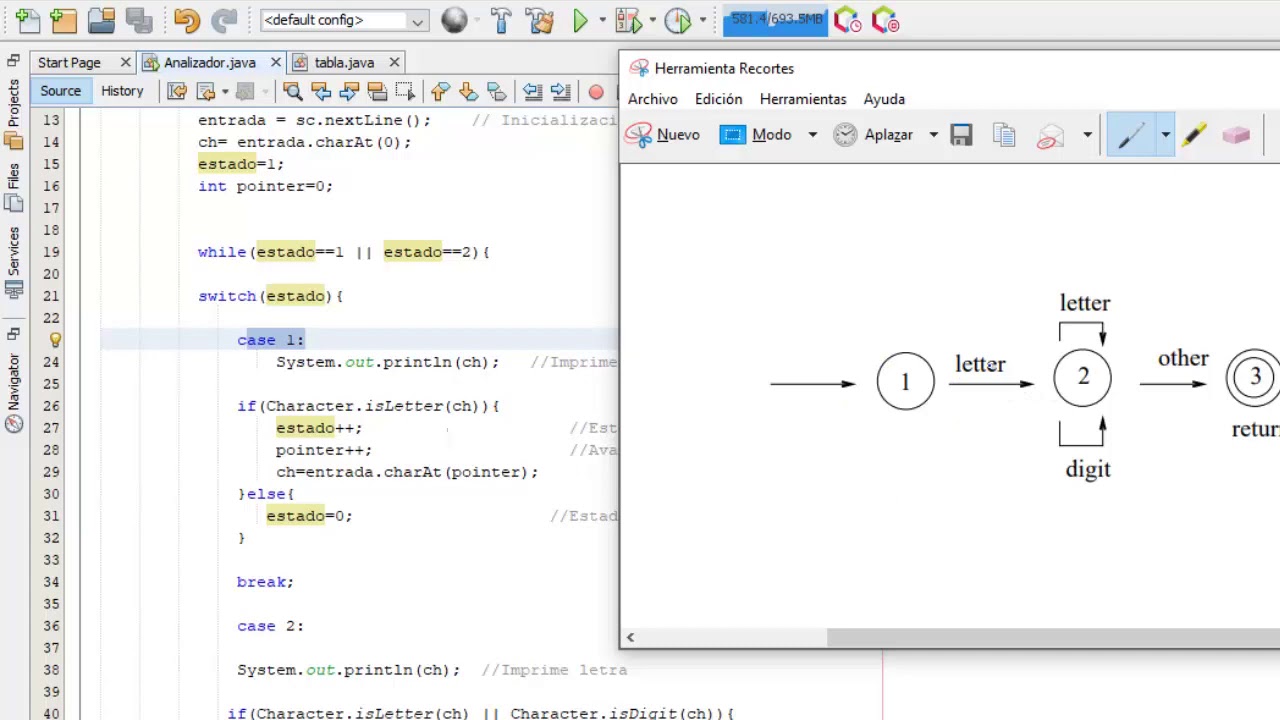
Se construye un Scanner (o Lexer) que itera sobre el código fuente. Para cada patrón, el Scanner intenta coincidir con el texto. Si una coincidencia se encuentra, se crea un token correspondiente. El token se asocia con su tipo y valor. ¿Qué estructura de datos se usa para representar los tokens?

Análisis Sintáctico
El siguiente paso es el Análisis Sintáctico. Aquí se verifica si la secuencia de tokens sigue las reglas gramaticales del lenguaje. Se construye un árbol de sintaxis abstracta (AST) que representa la estructura del programa.
Se puede utilizar un generador de parsers, como ANTLR o JavaCC. Estos generadores toman una gramática como entrada y producen código Java. Este código implementa el parser. Se decide qué tipo de parser usar: descendente (LL) o ascendente (LR). ¿Qué ventajas y desventajas tiene cada uno?
El parser recibe la secuencia de tokens del lexer. Luego, aplica las reglas gramaticales. Si el código es sintácticamente correcto, se construye el AST. Si hay errores sintácticos, se deben reportar. ¿Cómo se manejan los errores sintácticos y se recupera el parser?

Análisis Semántico
Finalmente, llegamos al Análisis Semántico. En esta etapa, se verifica el significado del código. Se comprueba la consistencia y validez del programa.
Esto incluye verificación de tipos. Se verifica que las operaciones se realicen sobre tipos de datos compatibles. Se comprueba si las variables están declaradas antes de ser usadas. Se busca errores de ámbito y otras inconsistencias semánticas. ¿Cómo se implementa la verificación de tipos en Java?

Durante el análisis semántico, se recorre el AST. Se recopila información sobre las variables, tipos y funciones. Esta información se almacena en tablas de símbolos. Se utiliza esta información para realizar las comprobaciones semánticas. ¿Qué estructura de datos se usa para las tablas de símbolos?
Si se encuentran errores semánticos, se reportan. Se indica el tipo de error y la ubicación en el código fuente. Un análisis semántico robusto ayuda a prevenir errores en tiempo de ejecución. ¿Cómo se diseñan mensajes de error significativos?
En resumen, la construcción de un analizador requiere una planificación cuidadosa. Se necesita elegir las herramientas adecuadas y comprender profundamente la gramática y semántica del lenguaje. Cada etapa se basa en la anterior. La calidad de cada etapa afecta la calidad general del analizador.