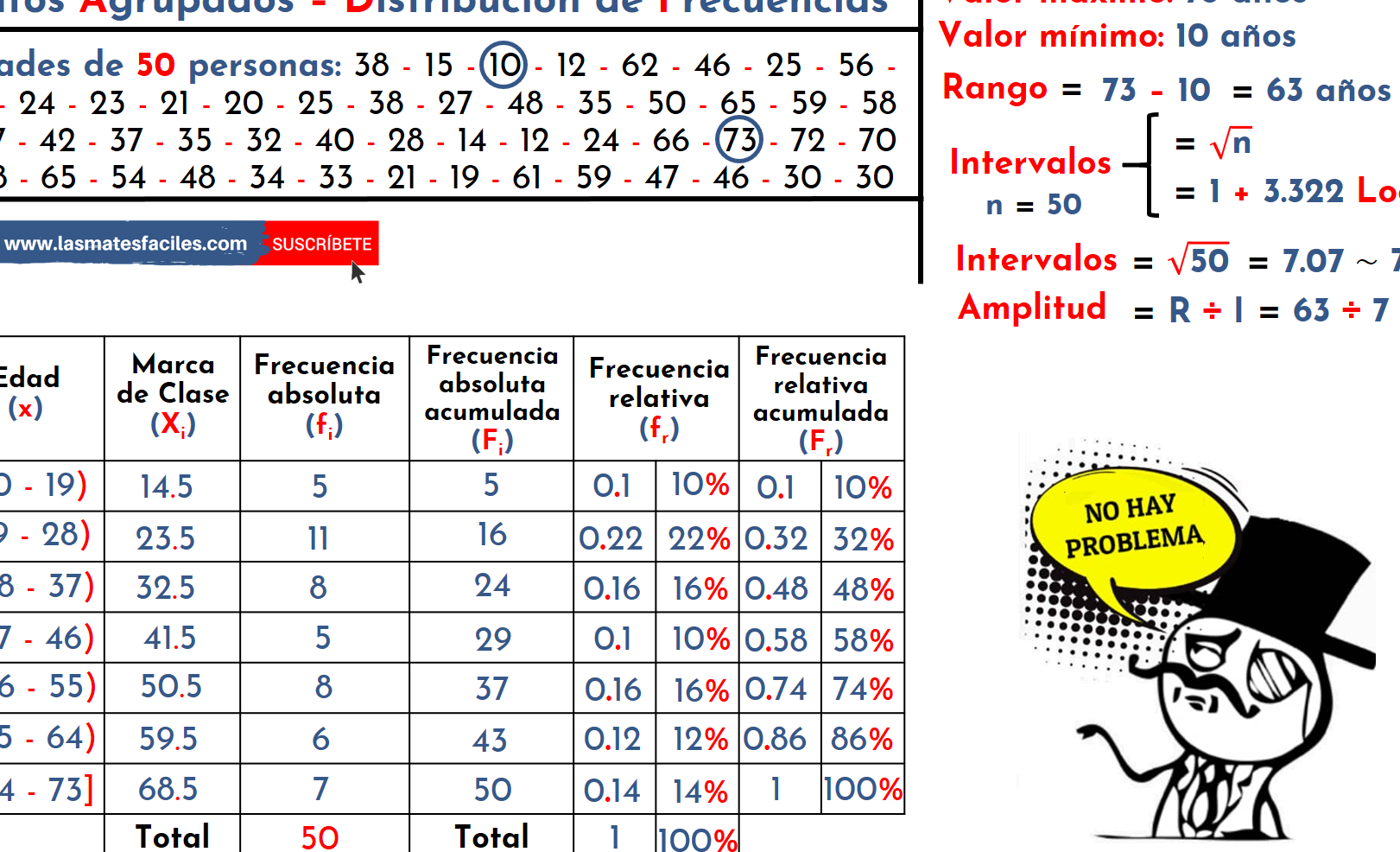
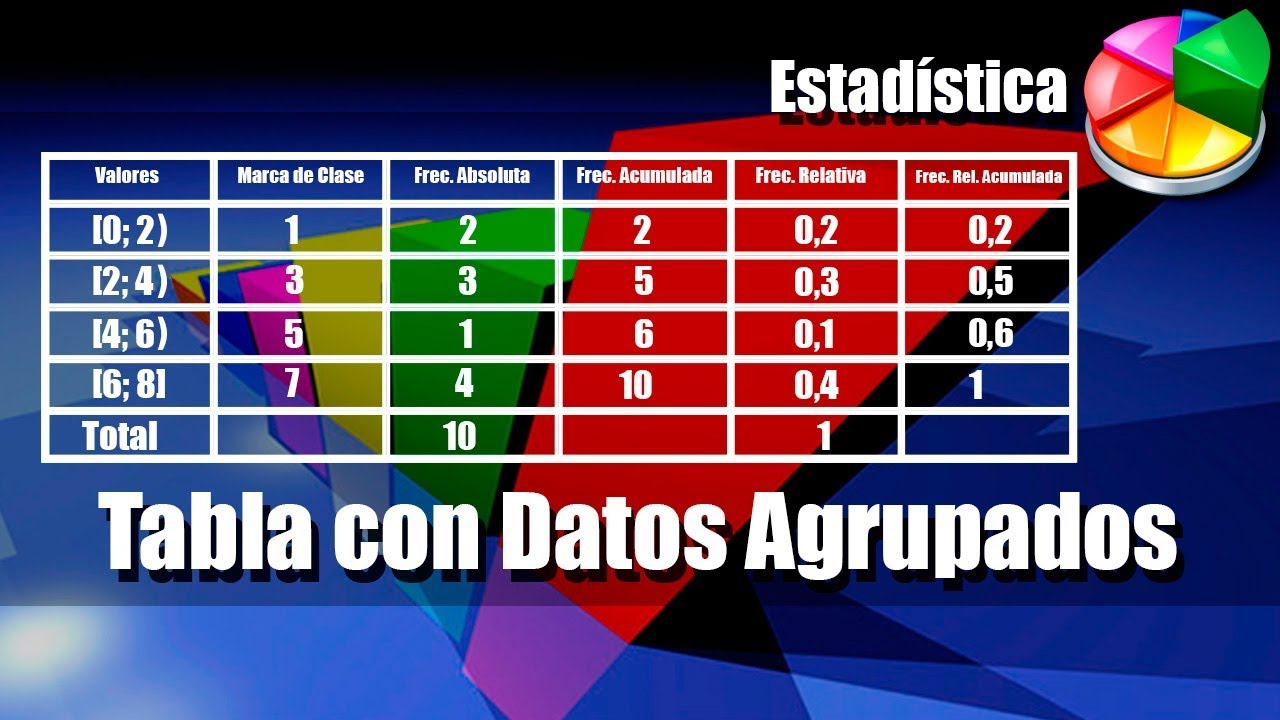
¡Hola a todos! Vamos a explorar las técnicas de agrupación de datos en probabilidad y estadística. Piensa en ello como organizar tu habitación. Tenemos un montón de cosas, y necesitamos ponerlas en orden.
Agrupación por Similitud: El Clúster
La agrupación por similitud, o "clustering," es como juntar calcetines que combinan. Imagina que tienes un montón de puntos en un gráfico. Algunos puntos están cerca unos de otros. Esos puntos forman un "clúster."
Piensa en clientes en una tienda. Algunos clientes compran cosas parecidas. Podríamos agruparlos en clústeres según sus compras. Esto nos ayuda a entender mejor a nuestros clientes. Visualízalo como formar grupos de amigos que tienen gustos similares.
Must Read
Hay diferentes maneras de hacer esto. El algoritmo K-means es uno popular. Le dices al algoritmo cuántos grupos quieres. El algoritmo encuentra los centros de esos grupos. Luego, asigna cada punto al centro más cercano. Es como asignar estudiantes a diferentes equipos.
La belleza de esto es que no necesitas saber de antemano a qué grupo pertenece cada dato. El algoritmo lo descubre por sí mismo. Es una herramienta poderosa para explorar datos.

Agrupación Jerárquica: El Árbol Genealógico
La agrupación jerárquica crea una estructura de árbol. Imagina un árbol genealógico. Comienzas con los individuos y los unes en familias. Luego unes familias en ramas más grandes.
En la agrupación jerárquica, cada dato comienza como su propio grupo. Luego, los grupos más cercanos se fusionan. Esto continúa hasta que todos los datos están en un solo grupo. Podemos ver la historia de cómo se forman los grupos.
Visualiza un mapa del mundo. Primero, podríamos agrupar ciudades cercanas. Luego, agruparíamos regiones. Finalmente, agruparíamos continentes. La agrupación jerárquica nos muestra estas conexiones paso a paso.

Hay dos enfoques principales: aglomerativo (de abajo hacia arriba) y divisivo (de arriba hacia abajo). El aglomerativo comienza con cada dato como un grupo único y los fusiona progresivamente. El divisivo comienza con un solo grupo grande y lo divide en grupos más pequeños.
Agrupación por Densidad: El Bosque
La agrupación por densidad busca áreas densas de datos. Imagina un bosque. Hay áreas donde los árboles están muy juntos. Esas son las áreas densas.
El algoritmo DBSCAN es un ejemplo. Busca puntos que tienen muchos vecinos cerca. Estos puntos forman un "núcleo." Los puntos que están cerca de los núcleos también se agregan al grupo. Puntos aislados, sin muchos vecinos, se consideran ruido.

Piensa en una multitud en un concierto. Hay áreas donde la gente está muy junta. DBSCAN identificaría estas áreas densas. Los individuos más alejados se considerarían fuera de la multitud principal.
A diferencia de K-means, DBSCAN no requiere que especifiques el número de clústeres de antemano. Esto es útil cuando no tienes idea de cuántos grupos existen. Además, puede identificar formas no convexas, como espirales o lunas crecientes.
La Importancia de la Distancia
Un concepto clave en todas estas técnicas es la distancia. ¿Qué tan lejos están dos puntos entre sí? Diferentes medidas de distancia pueden llevar a diferentes resultados.

La distancia euclidiana es la más común. Es la distancia en línea recta entre dos puntos. Piensa en medir la distancia entre dos ciudades en un mapa.
Otras distancias incluyen la distancia Manhattan (como caminar por calles en una ciudad) y la distancia de coseno (que mide la similitud en dirección, no en magnitud). Elegir la distancia correcta es crucial para obtener resultados significativos.
En resumen, las técnicas de agrupación de datos son herramientas poderosas. Nos ayudan a encontrar patrones y estructuras ocultas en nuestros datos. ¡Así que, a explorar y descubrir!