Comenzaremos la construcción de una tabla de distribución de frecuencias para datos no agrupados. Esto se hace paso a paso. Cada paso es crucial para obtener la tabla correcta. El primer paso es recolectar los datos.
Supongamos que tenemos los siguientes datos: 1, 2, 2, 3, 3, 3, 4, 4, 5. Son datos no agrupados. Estos datos representan las respuestas de una encuesta. La encuesta pregunta cuántos libros leyeron el mes pasado.
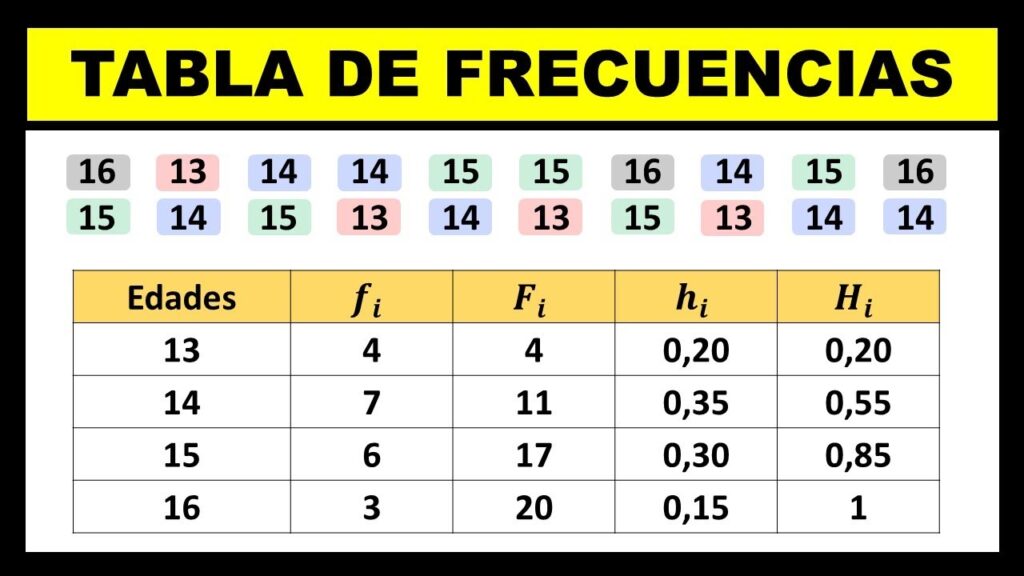
Paso 1: Identificar el rango de los datos
El rango es la diferencia entre el valor máximo y el valor mínimo. En nuestro caso, el valor máximo es 5. El valor mínimo es 1. Entonces, el rango es 5 - 1 = 4.
Must Read
Paso 2: Crear una tabla con las columnas necesarias
Nuestra tabla tendrá varias columnas. La primera columna será para la variable (xi). La segunda columna será para la frecuencia absoluta (fi). La tercera columna será para la frecuencia acumulada (Fi). La cuarta columna será para la frecuencia relativa (hi). La quinta columna será para la frecuencia relativa acumulada (Hi).
Paso 3: Llenar la columna de la variable (xi)
La columna xi representa los valores únicos en nuestros datos. En nuestro ejemplo, los valores únicos son 1, 2, 3, 4 y 5. Los escribiremos en la primera columna. Cada valor debe aparecer solo una vez.

Paso 4: Calcular la frecuencia absoluta (fi)
La frecuencia absoluta (fi) es el número de veces que aparece cada valor. 1 aparece una vez, por lo tanto, f1 = 1. 2 aparece dos veces, por lo tanto, f2 = 2. 3 aparece tres veces, por lo tanto, f3 = 3. 4 aparece dos veces, por lo tanto, f4 = 2. 5 aparece una vez, por lo tanto, f5 = 1.
A continuación, sumamos todas las frecuencias absolutas (fi). La suma es 1 + 2 + 3 + 2 + 1 = 9. Este valor (9) representa el tamaño total de la muestra (n). Es decir, hay 9 datos en total. Este valor nos servirá para calcular la frecuencia relativa.
Paso 5: Calcular la frecuencia acumulada (Fi)
La frecuencia acumulada (Fi) se calcula sumando las frecuencias absolutas de forma acumulativa. F1 es igual a f1, entonces F1 = 1. F2 es igual a F1 + f2, entonces F2 = 1 + 2 = 3. F3 es igual a F2 + f3, entonces F3 = 3 + 3 = 6. F4 es igual a F3 + f4, entonces F4 = 6 + 2 = 8. F5 es igual a F4 + f5, entonces F5 = 8 + 1 = 9.
El último valor de la frecuencia acumulada (F5) debe ser igual al tamaño total de la muestra (n). En nuestro caso, ambos son 9. Esto nos ayuda a verificar que no cometimos errores al sumar.
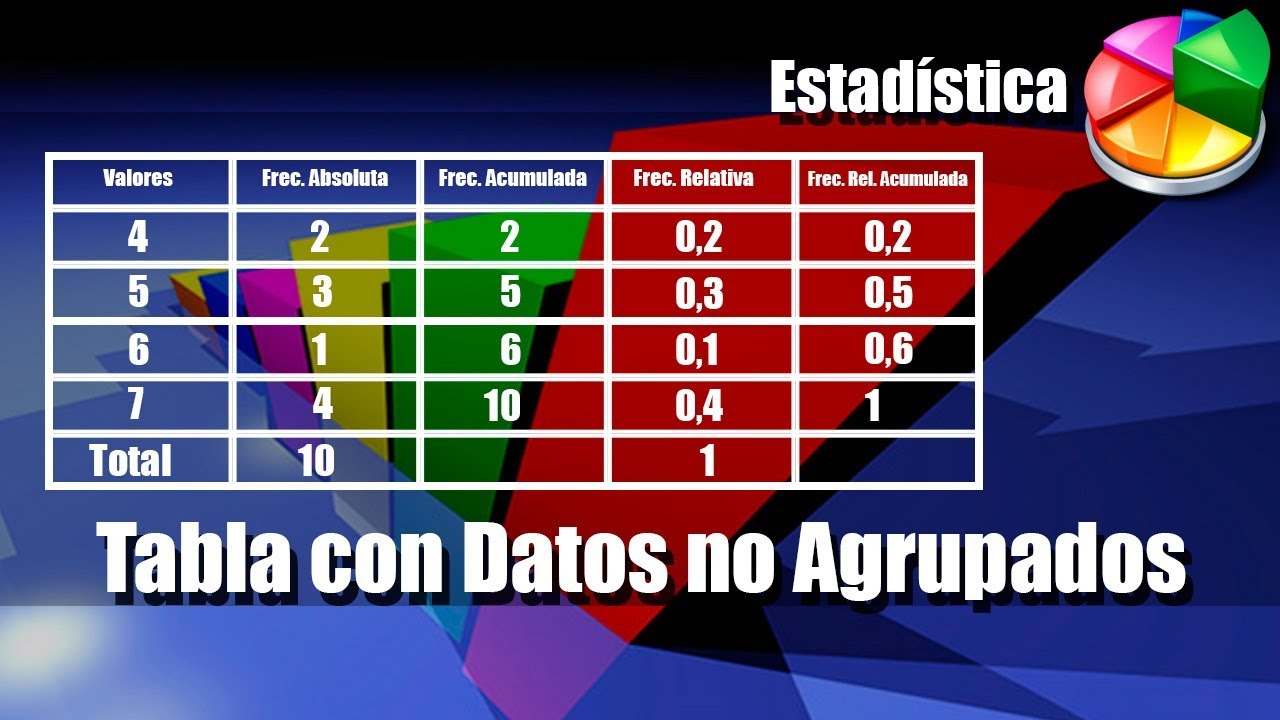
Paso 6: Calcular la frecuencia relativa (hi)
La frecuencia relativa (hi) se calcula dividiendo la frecuencia absoluta (fi) por el tamaño total de la muestra (n). Entonces, h1 = f1 / n = 1 / 9 = 0.11. h2 = f2 / n = 2 / 9 = 0.22. h3 = f3 / n = 3 / 9 = 0.33. h4 = f4 / n = 2 / 9 = 0.22. h5 = f5 / n = 1 / 9 = 0.11.
Sumamos todas las frecuencias relativas (hi). La suma debe ser igual a 1 (o muy cercana a 1 debido al redondeo). 0.11 + 0.22 + 0.33 + 0.22 + 0.11 = 0.99. Es aceptable una pequeña diferencia debido al redondeo.

Paso 7: Calcular la frecuencia relativa acumulada (Hi)
La frecuencia relativa acumulada (Hi) se calcula sumando las frecuencias relativas de forma acumulativa. H1 es igual a h1, entonces H1 = 0.11. H2 es igual a H1 + h2, entonces H2 = 0.11 + 0.22 = 0.33. H3 es igual a H2 + h3, entonces H3 = 0.33 + 0.33 = 0.66. H4 es igual a H3 + h4, entonces H4 = 0.66 + 0.22 = 0.88. H5 es igual a H4 + h5, entonces H5 = 0.88 + 0.11 = 0.99.
El último valor de la frecuencia relativa acumulada (H5) debe ser igual a 1 (o muy cercano a 1 debido al redondeo). En nuestro caso, es 0.99. Esto confirma que los cálculos son correctos.
Hemos completado todos los pasos para construir la tabla de distribución de frecuencias para datos no agrupados. La tabla resultante contiene toda la información relevante sobre la distribución de nuestros datos.