Las medidas de tendencia central son valores que representan un conjunto de datos. En datos agrupados (datos organizados en intervalos o clases), calculamos estas medidas usando fórmulas ligeramente diferentes a las usadas para datos no agrupados. Nos ayudan a encontrar un valor típico o promedio para la distribución.
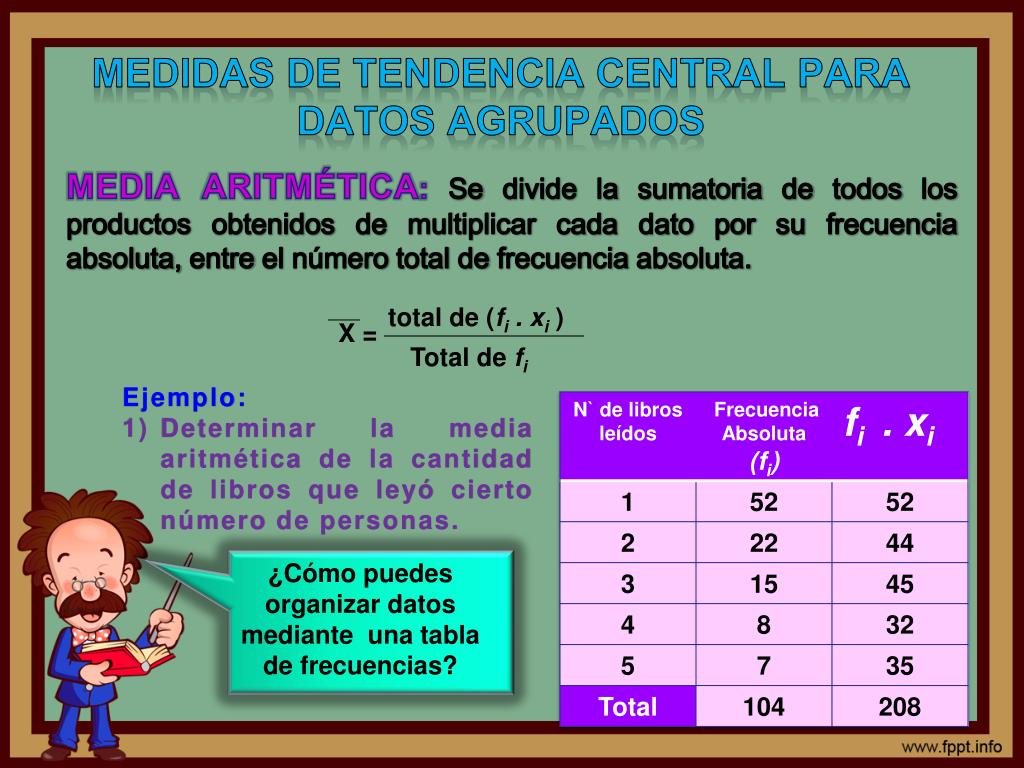
Media Aritmética (Promedio): La media es la suma de todos los valores multiplicados por su frecuencia, dividida por el número total de datos.
Fórmula: X̄ = Σ(fi * xi) / N
Must Read
Donde:
- X̄ es la media
- fi es la frecuencia de la clase i
- xi es la marca de clase (punto medio del intervalo) de la clase i
- N es el número total de datos (Σfi)
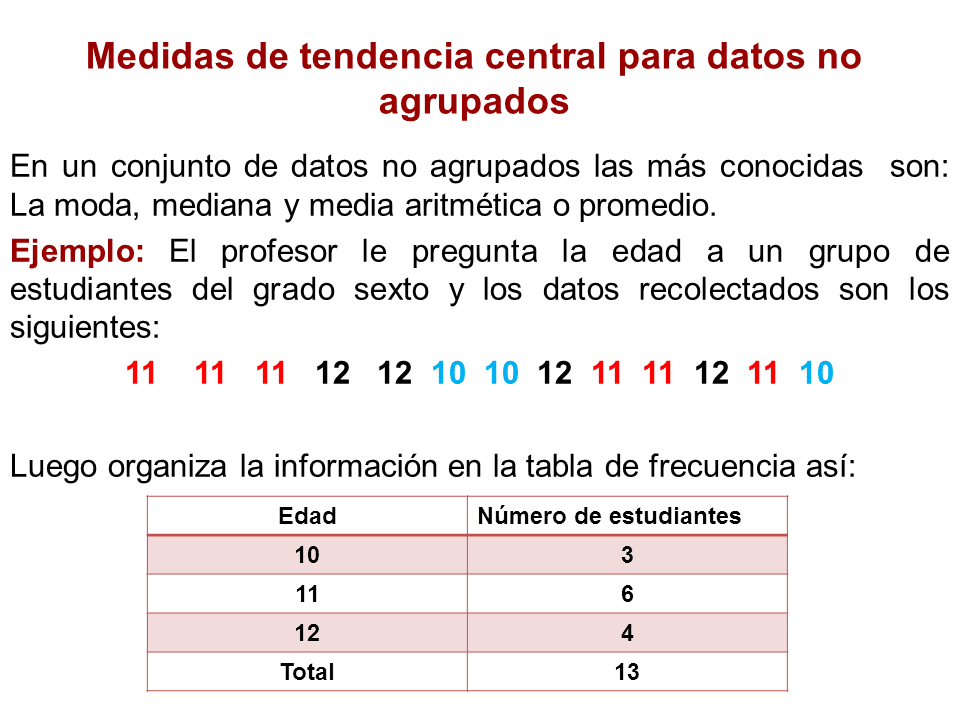
Ejemplo: Supongamos que tenemos las siguientes clases de edades y sus frecuencias:

Edad (intervalo) | Frecuencia ------------------|----------- 10-20 | 5 20-30 | 10 30-40 | 15
Primero, encontramos la marca de clase (punto medio) de cada intervalo: 15, 25, 35. Luego, multiplicamos cada marca de clase por su frecuencia: (155), (2510), (35*15) = 75, 250, 525. Sumamos estos productos: 75 + 250 + 525 = 850. Finalmente, dividimos por el número total de datos (5+10+15 = 30): 850 / 30 = 28.33. La media es 28.33.
Mediana: La mediana es el valor que se encuentra en el medio de los datos. En datos agrupados, primero debemos encontrar la clase mediana (la clase que contiene la mediana). Esta es la clase cuya frecuencia acumulada supera la mitad del número total de datos (N/2).
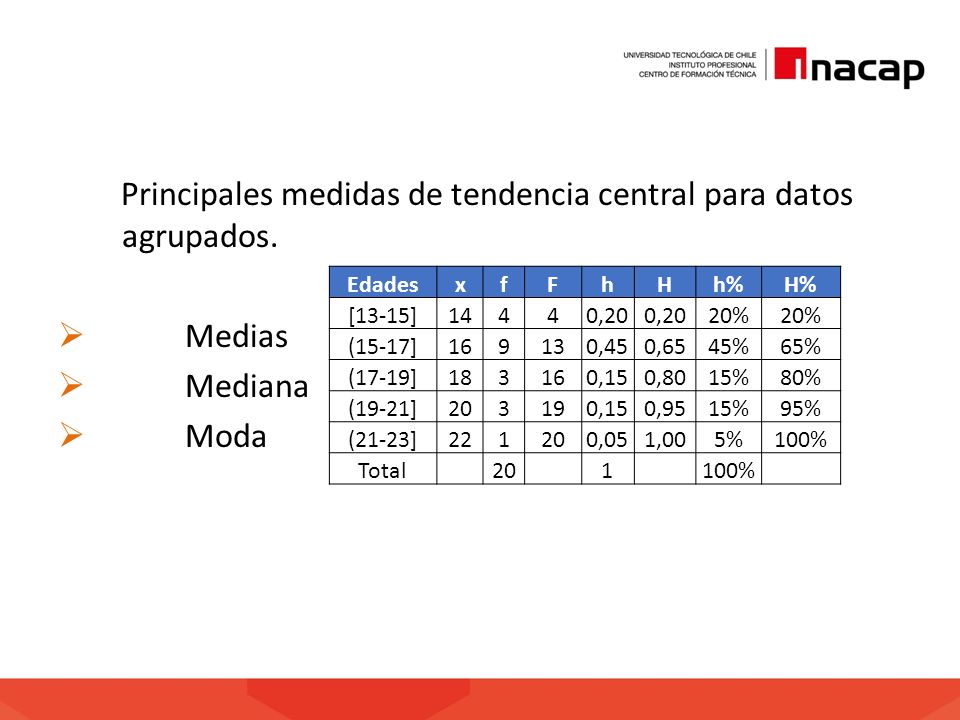
Fórmula: Me = L + [(N/2 - Fant) / fmed] * c
Donde:
- Me es la mediana
- L es el límite inferior de la clase mediana
- N es el número total de datos
- Fant es la frecuencia acumulada de la clase anterior a la clase mediana
- fmed es la frecuencia de la clase mediana
- c es la amplitud del intervalo de clase
Moda: La moda es el valor que más se repite. En datos agrupados, identificamos la clase modal (la clase con la mayor frecuencia). Luego, podemos usar una fórmula para aproximar la moda dentro de esa clase.
Fórmula (aproximación simple): La moda puede estimarse simplemente como la marca de clase de la clase modal.
Estas medidas ayudan a tener una idea centralizada de la distribución de datos, aunque la interpretación es diferente a los datos no agrupados.