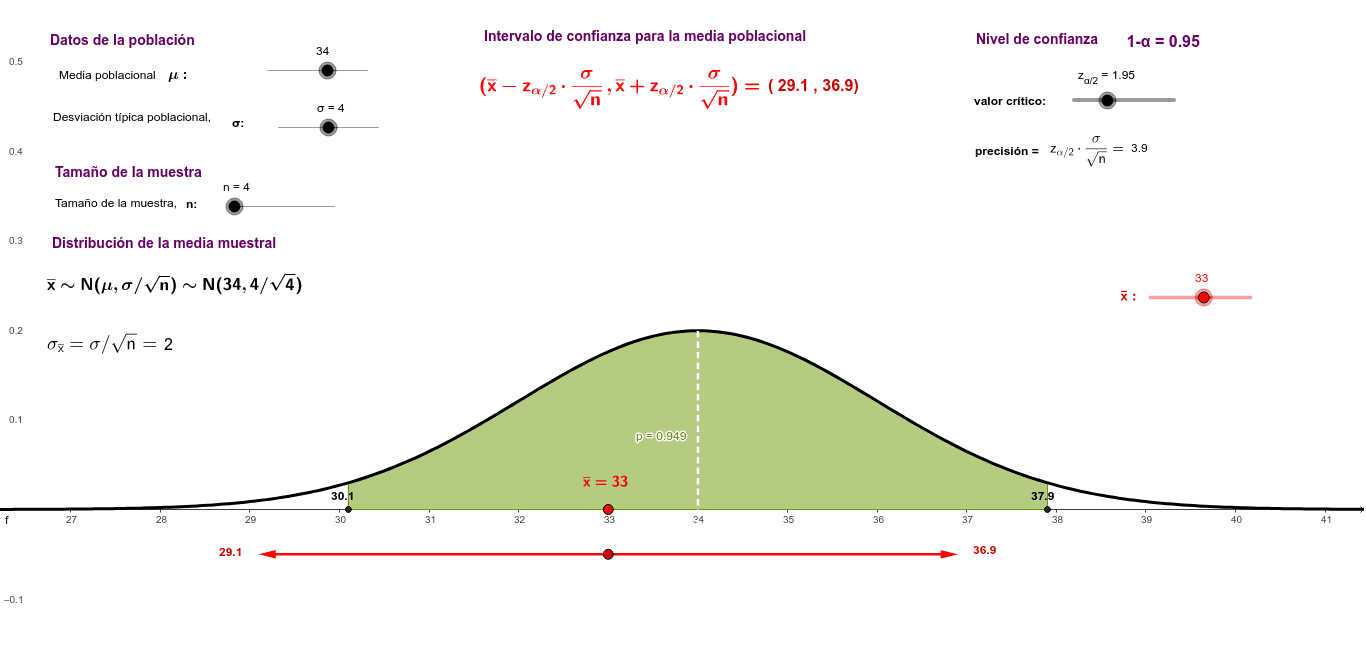
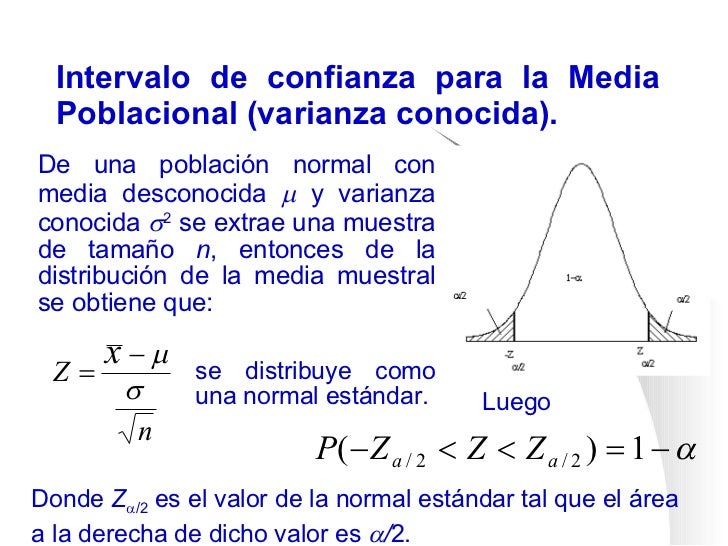
Un intervalo de confianza es un rango de valores que, con cierta probabilidad, contiene el verdadero valor de un parámetro poblacional desconocido. En nuestro caso, nos centraremos en el intervalo de confianza para la media poblacional (μ).
¿Qué necesitamos para calcularlo?
Para construir un intervalo de confianza para la media, necesitamos varios elementos clave. Primero, la media muestral (x̄), que es el promedio de los datos que hemos recolectado. Segundo, la desviación estándar (σ o s). Tercero, el tamaño de la muestra (n). Cuarto, el nivel de confianza (1-α).
El nivel de confianza indica la probabilidad de que el intervalo contenga el verdadero valor de la media poblacional. Comúnmente, se utilizan niveles de confianza del 90%, 95% o 99%. El valor de α representa el nivel de significancia, que es el complemento del nivel de confianza (α = 1 - nivel de confianza).
Must Read
Dependiendo de si conocemos la desviación estándar poblacional (σ) o solo la muestral (s), usaremos la distribución Z o la distribución t, respectivamente.
Caso 1: Desviación estándar poblacional conocida (σ)
Si conocemos la desviación estándar poblacional (σ), utilizamos la distribución Z (normal estándar) para calcular el intervalo de confianza. La fórmula general es: x̄ ± Zα/2 * (σ / √n)
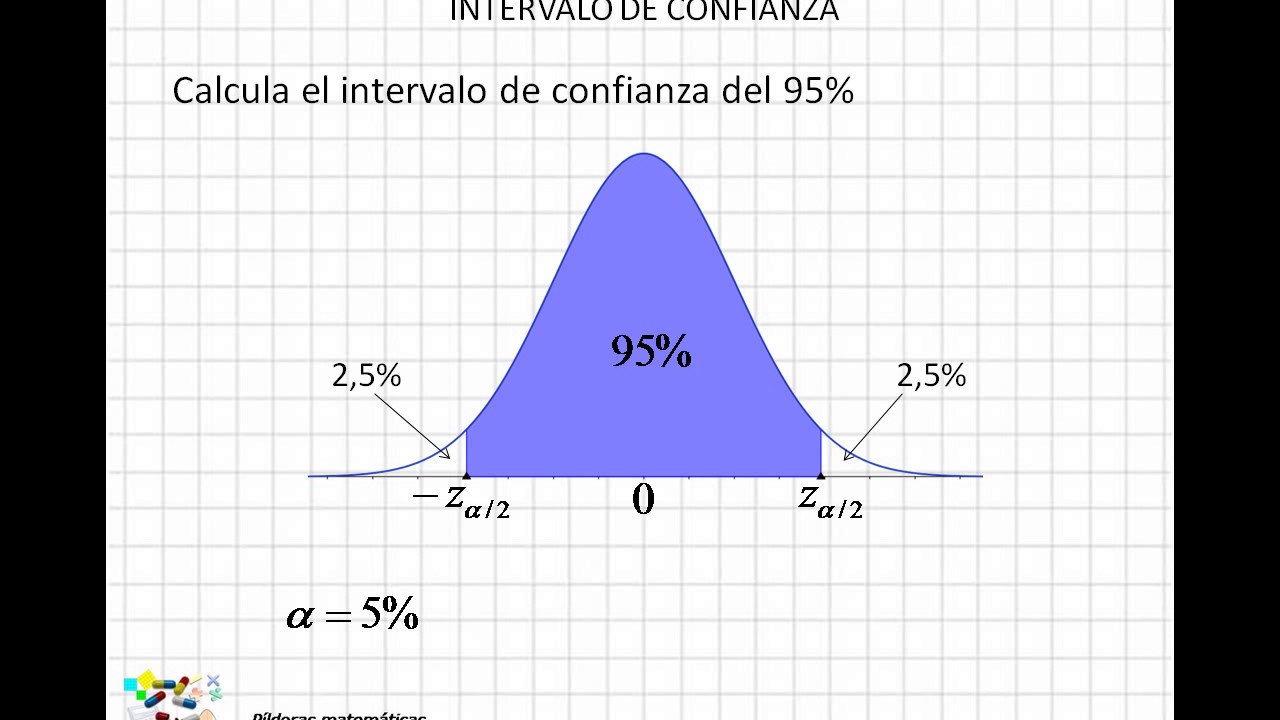
Aquí, Zα/2 es el valor crítico de la distribución Z que corresponde al nivel de significancia α/2. Por ejemplo, para un nivel de confianza del 95% (α = 0.05), Zα/2 = 1.96.
Ejemplo: Supongamos que queremos estimar la edad promedio de todos los estudiantes de una universidad. Tomamos una muestra aleatoria de 100 estudiantes y encontramos que la edad promedio (x̄) es de 22 años. Sabemos, por estudios anteriores, que la desviación estándar poblacional (σ) es de 3 años. Queremos un nivel de confianza del 95%.

Aplicando la fórmula: 22 ± 1.96 * (3 / √100) = 22 ± 0.588. El intervalo de confianza es (21.412, 22.588). Con un 95% de confianza, podemos decir que la edad promedio de todos los estudiantes de la universidad está entre 21.412 y 22.588 años.
Caso 2: Desviación estándar poblacional desconocida (s)
Si no conocemos la desviación estándar poblacional (σ), usamos la desviación estándar muestral (s) y la distribución t de Student. La fórmula es: x̄ ± tα/2, n-1 * (s / √n)
Aquí, tα/2, n-1 es el valor crítico de la distribución t con n-1 grados de libertad que corresponde al nivel de significancia α/2. Los grados de libertad reflejan la cantidad de información independiente disponible para estimar la variabilidad.

Ejemplo: Queremos estimar el peso promedio de un tipo específico de manzana. Tomamos una muestra de 25 manzanas y encontramos que el peso promedio (x̄) es de 150 gramos, con una desviación estándar muestral (s) de 15 gramos. Queremos un nivel de confianza del 99%.
Como la desviación estándar poblacional es desconocida, usamos la distribución t. Con n-1 = 24 grados de libertad y α = 0.01 (nivel de confianza del 99%), tα/2, 24 ≈ 2.797. Aplicando la fórmula: 150 ± 2.797 * (15 / √25) = 150 ± 8.391. El intervalo de confianza es (141.609, 158.391).
.jpg)
Con un 99% de confianza, podemos decir que el peso promedio de este tipo de manzana está entre 141.609 y 158.391 gramos.
Importancia del tamaño de la muestra
El tamaño de la muestra (n) influye en la amplitud del intervalo de confianza. A mayor tamaño de la muestra, menor es la amplitud del intervalo, lo que significa una estimación más precisa de la media poblacional. Un intervalo más estrecho nos da más certeza sobre dónde se encuentra el verdadero valor de la media.
En resumen, el intervalo de confianza para la media poblacional nos proporciona un rango de valores plausibles para la media real, basado en la información de la muestra y un nivel de confianza deseado. Su cálculo y correcta interpretación son fundamentales en la inferencia estadística.