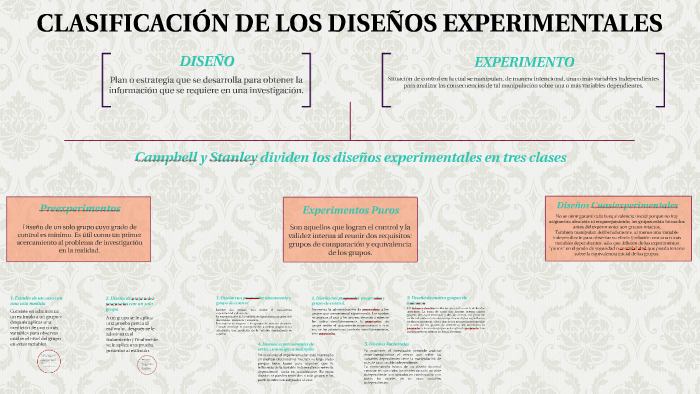
El concepto de "Familia de Diseños para Comparar Tratamientos" se refiere a un conjunto de métodos estadísticos usados para evaluar la efectividad de diferentes tratamientos.
Estos diseños son cruciales en la investigación, especialmente en áreas como la medicina, la agricultura y las ciencias sociales. Los diseños nos ayudan a determinar si un tratamiento realmente funciona.
Paso 1: Identificar el Problema o Pregunta
Primero, debemos identificar claramente qué queremos investigar. ¿Queremos comparar la efectividad de dos medicamentos para la presión arterial? ¿O quizás comparar diferentes métodos de enseñanza para mejorar el rendimiento académico? Es importante definir la pregunta de investigación.
Must Read
Un ejemplo: ¿Cuál de tres fertilizantes (A, B, y C) produce el mayor rendimiento en un cultivo de maíz?
Paso 2: Seleccionar el Diseño de Estudio Apropiado
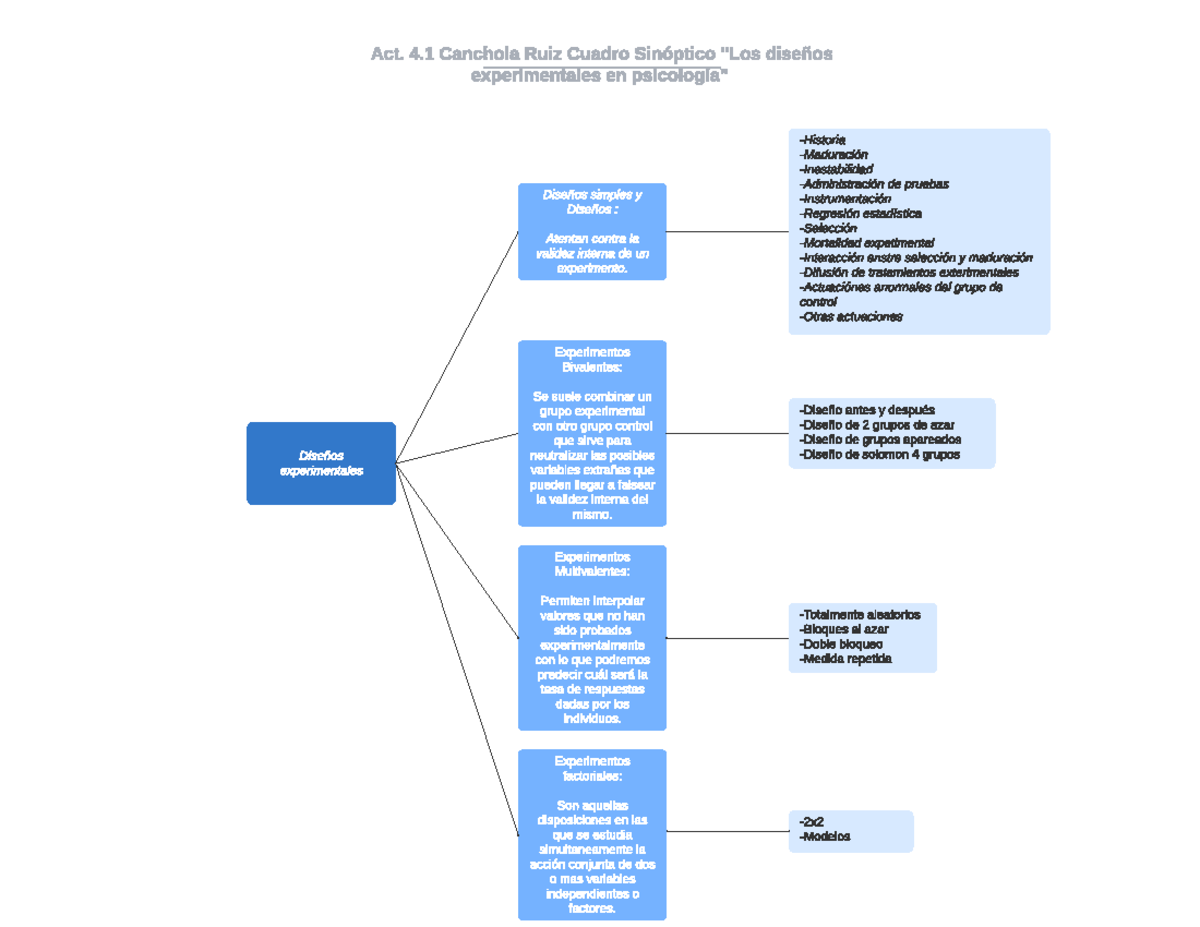
Existen varios tipos de diseños que podemos usar, dependiendo de la naturaleza de la pregunta y los recursos disponibles. Algunos diseños comunes incluyen:

- Ensayos Controlados Aleatorizados (ECA): Son considerados el "estándar de oro" porque asignan participantes aleatoriamente a diferentes grupos de tratamiento.
- Estudios Observacionales: En estos estudios, los investigadores observan y registran datos sin intervenir ni asignar tratamientos.
- Diseños Factoriales: Permiten evaluar el efecto de dos o más factores (tratamientos) simultáneamente y sus interacciones.
- Diseños de Bloques Aleatorizados: Se utilizan para reducir la variabilidad al agrupar las unidades experimentales en bloques homogéneos.
Para nuestro ejemplo del fertilizante, un diseño de bloques aleatorizados sería apropiado si la calidad del suelo varía en el campo. Dividiríamos el campo en bloques con suelo similar y luego asignaríamos aleatoriamente los fertilizantes A, B y C dentro de cada bloque.
Paso 3: Definir las Variables
Identifica las variables independientes (el tratamiento) y dependientes (el resultado que medimos). En nuestro ejemplo, el fertilizante (A, B, C) es la variable independiente. El rendimiento del maíz (kilogramos por hectárea) es la variable dependiente.
También es crucial identificar posibles variables de confusión que podrían afectar los resultados. Por ejemplo, la cantidad de agua que recibe cada parcela.

Paso 4: Recolectar los Datos
Debemos recolectar los datos de manera cuidadosa y precisa. En nuestro ejemplo, esto significa medir el rendimiento del maíz en cada parcela tratada con cada fertilizante.
Asegúrate de registrar la información de forma organizada para facilitar el análisis posterior.
Paso 5: Analizar los Datos
Utilizamos métodos estadísticos para analizar los datos y determinar si existen diferencias significativas entre los tratamientos. El tipo de análisis depende del diseño del estudio.
Para el ejemplo del fertilizante, podríamos usar un ANOVA (Análisis de Varianza) para comparar el rendimiento promedio del maíz para cada fertilizante. El ANOVA nos dirá si hay diferencias significativas entre los grupos.
Paso 6: Interpretar los Resultados
Interpretamos los resultados del análisis estadístico para responder a nuestra pregunta de investigación. ¿Hubo una diferencia significativa en el rendimiento del maíz entre los fertilizantes?

Si encontramos una diferencia significativa, debemos considerar la magnitud de la diferencia y su relevancia práctica. Un fertilizante puede ser estadísticamente superior, pero la diferencia en rendimiento puede ser tan pequeña que no justifique el costo adicional.
Paso 7: Sacar Conclusiones
Finalmente, sacamos conclusiones basadas en la evidencia. ¿Podemos concluir que uno de los fertilizantes es mejor que los otros para aumentar el rendimiento del maíz? ¿Necesitamos más investigación?
Es importante reconocer las limitaciones del estudio y evitar generalizaciones excesivas. Nuestras conclusiones solo son válidas para las condiciones específicas en las que se realizó el estudio.