
Para extraer texto de una imagen usando Python, necesitas seguir varios pasos. Estos pasos involucran la instalación de bibliotecas necesarias y la escritura del código.
Paso 1: Instalar las bibliotecas necesarias
Primero, necesitas instalar las bibliotecas Tesseract OCR y Pytesseract. Tesseract OCR es el motor de reconocimiento óptico de caracteres (OCR). Pytesseract es un envoltorio de Python para Tesseract.
Puedes instalar Tesseract OCR dependiendo de tu sistema operativo. En Windows, descarga el instalador desde una fuente confiable e instálalo. Asegúrate de añadir la ruta de instalación a las variables de entorno del sistema.
Must Read
Para Linux (Debian/Ubuntu), puedes usar el siguiente comando en la terminal:
sudo apt update
sudo apt install tesseract-ocrUna vez instalado Tesseract OCR, instala Pytesseract usando pip:
pip install pytesseract
pip install pillowNecesitarás la biblioteca Pillow para trabajar con imágenes.

Paso 2: Importar las bibliotecas
En tu script de Python, importa las bibliotecas Pytesseract y PIL (Pillow):
from PIL import Image
import pytesseractEsto permite usar las funciones de ambas bibliotecas.
Paso 3: Configurar la ruta de Tesseract
Pytesseract necesita saber dónde está instalado Tesseract OCR. Configura la ruta a Tesseract en tu código.

Por ejemplo, si instalaste Tesseract en `C:\Program Files\Tesseract-OCR`, el código sería:
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'Asegúrate de reemplazar la ruta con la ubicación correcta en tu sistema.
Paso 4: Abrir la imagen
Abre la imagen que contiene el texto usando Pillow:
img = Image.open('nombre_de_la_imagen.png')Reemplaza `nombre_de_la_imagen.png` con el nombre de tu archivo de imagen.
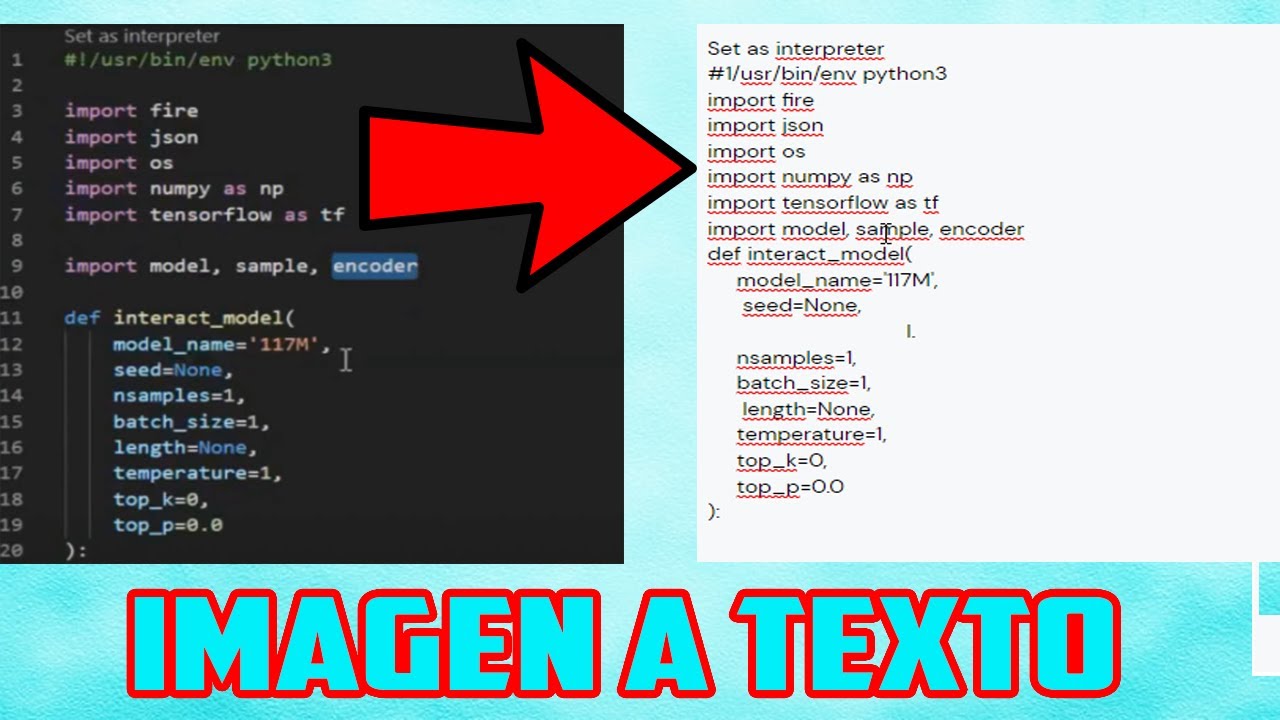
Paso 5: Extraer el texto de la imagen
Usa la función `image_to_string()` de Pytesseract para extraer el texto:
texto = pytesseract.image_to_string(img)Esto convierte la imagen en texto.
Paso 6: Imprimir el texto extraído
Imprime el texto extraído:

print(texto)Esto mostrará el texto reconocido en la consola.
Código Completo de Ejemplo
Aquí está el código completo:
from PIL import Image
import pytesseract
# Configurar la ruta de Tesseract (ajusta la ruta según tu instalación)
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# Abrir la imagen
img = Image.open('nombre_de_la_imagen.png')
# Extraer el texto
texto = pytesseract.image_to_string(img, lang='spa') # 'spa' para español
# Imprimir el texto
print(texto)
Recuerda reemplazar `'nombre_de_la_imagen.png'` con el nombre real de tu archivo de imagen. Además, se agregó el parámetro `lang='spa'` para indicar que el texto en la imagen está en español, lo que puede mejorar la precisión del reconocimiento.
Considera que la calidad de la imagen afecta la precisión del OCR. Imágenes claras y bien definidas darán mejores resultados.





