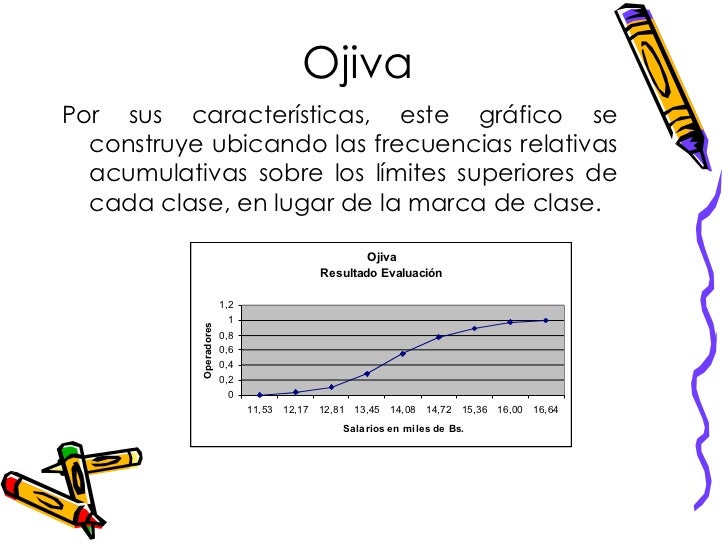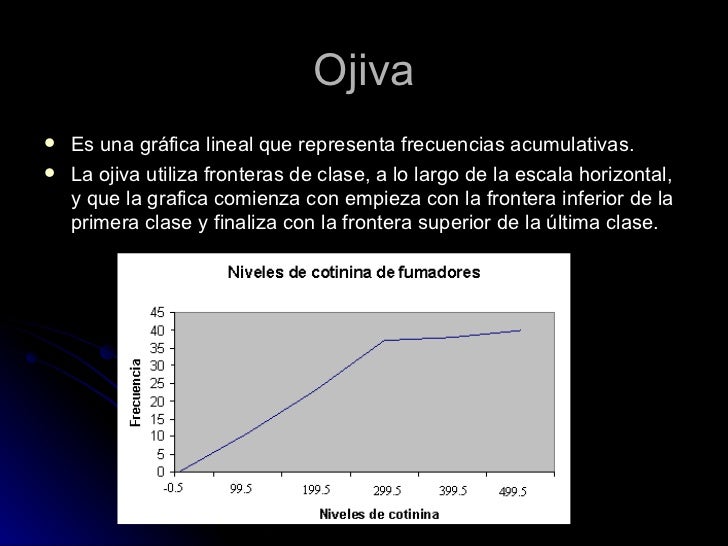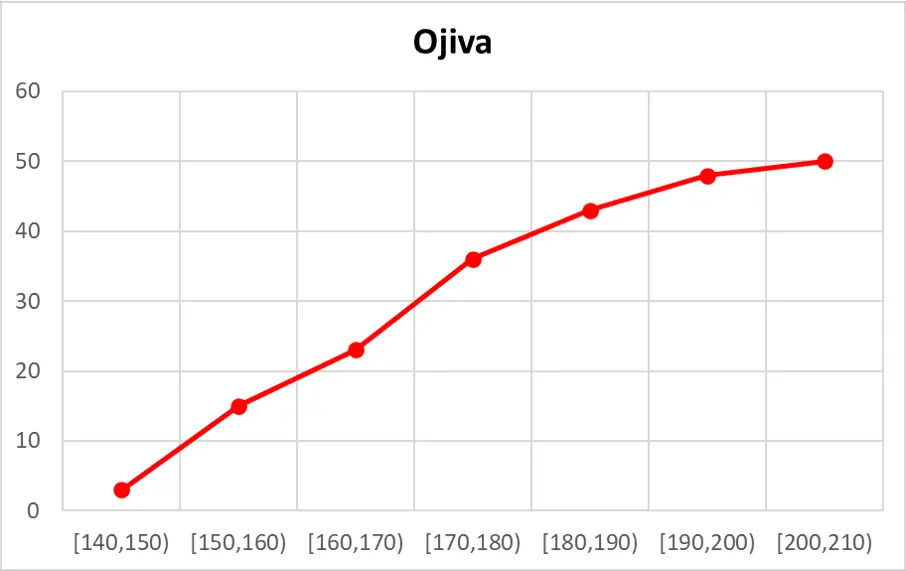
La ojiva, también conocida como curva de frecuencia acumulada, se construye utilizando principalmente dos tipos de datos: las frecuencias absolutas acumuladas y los límites superiores de los intervalos de clase.
El primer paso es organizar los datos en una tabla de frecuencias. Esta tabla debe contener los intervalos de clase (rangos de valores), la frecuencia absoluta de cada intervalo (cuántas observaciones caen dentro de cada intervalo) y la frecuencia absoluta acumulada de cada intervalo. La frecuencia absoluta acumulada se calcula sumando las frecuencias absolutas de todos los intervalos anteriores al actual, incluyendo el propio intervalo.
Una vez que tienes la tabla de frecuencias completa, necesitas los límites superiores de cada intervalo. Estos límites son los valores más altos de cada intervalo de clase. La ojiva se construye graficando estos límites superiores en el eje horizontal (eje x) y las frecuencias absolutas acumuladas correspondientes en el eje vertical (eje y).
Must Read
Cada par de coordenadas (límite superior, frecuencia absoluta acumulada) se marca como un punto en el gráfico. Luego, se conectan estos puntos con líneas rectas, comenzando desde el punto (límite inferior del primer intervalo, 0). La línea resultante es la ojiva.
Ejemplo: Imagina que tienes las siguientes edades de personas: 10-15, 15-20, 20-25, 25-30. Para la ojiva, necesitas las frecuencias acumuladas. Si las frecuencias son 5, 8, 12, y 5 respectivamente, las frecuencias acumuladas serían 5, 13, 25, y 30. Los límites superiores serían 15, 20, 25, y 30. Graficarías los puntos (15, 5), (20, 13), (25, 25), y (30, 30) y los conectarías.

Otro ejemplo: Considera los siguientes intervalos de puntuación en un examen: 50-60, 60-70, 70-80, 80-90, y 90-100. Si las frecuencias acumuladas correspondientes son 10, 30, 60, 80, y 100, la ojiva se construiría usando los límites superiores (60, 70, 80, 90, 100) y las frecuencias acumuladas correspondientes.
La ojiva se utiliza para visualizar la distribución de los datos y para determinar el número de observaciones que están por debajo de un cierto valor. Es particularmente útil para encontrar percentiles, cuartiles y otros estadísticos descriptivos. Su aplicación es común en campos como la estadística, la economía y el control de calidad para analizar y presentar datos de manera efectiva.